While the choice of private / hybrid / public cloud might become easier now with lot of awareness and information available on cloud storage addressing related security apprehensions, now choosing the right cloud partner becomes a larger matter.
In the public cloud computing market, three big vendors dominate: Amazon Web Services, Microsoft Azure and Google Cloud Platform (GCP) When it comes to infrastructure as a service (IaaS) and platform as a service (PaaS), these three have a huge lead on the rest of the market. However their approach is predominantly driven by their strengths and backgrounds. Amazon is the first mover amongst the three and hence has a wealth of experience in managing volumes of data. Microsoft being a technology giant has vast experience of computing. Google relatively new in cloud space, drive strength from data & analytics. So depending upon their strengths and offerings, you may have to weigh your options and may have to settle down for a combination depending upon your organization goals and long term objectives.
We’ll analyze the three giants in three major categories; Features, Implementation and Pricing.
Features
All three of AWS, GCP and Azure use different terminology, codes, and nomenclatures to define their cloud products.
All the three cloud players have their own way of categorizing the different elements. Hence it’s important to define your organization’s requirements in terms of current and future cloud space and data requirements. Once you have clear strategy in place, you can start working with cloud partners to devise best solution for your organization.
AWS

AWS Solutions cover a large degree of categorization, namely:
- Websites
- Backup and Recovery
- Archiving
- Disaster Recovery
- DevOps
- Big Data
Azure
Microsoft came late to the cloud market but gave itself a jump start by essentially taking its on-premises software – Windows Server, Office, SQL Server, SharePoint, Dynamics Active Directory, .Net, and others to the cloud.
Azure is tightly integrated with the other applications, Existing Microsoft customers or enterprises that use a lot of Microsoft software find it logical to go for Azure. Also, there is a significant discount off service contracts for existing Microsoft enterprise customers.
Azure operates by number of users
Azure boasts of maximum certifications from industry leaders and engagements with large organizations. Azure offers competitive pricing on committed usage.

With these certifications they believed this security can persuade organizations to place their trust in Microsoft. Like AWS, Azure equally provides an enormous array of features, and add value by providing certain capabilities based on the number of users.

GCP (Google Cloud Platform)
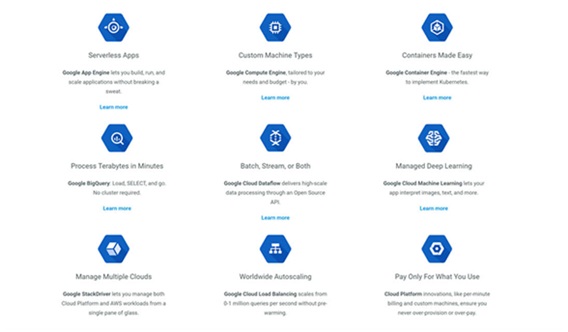
Lastly, you have the GCP (Google Cloud platform), which while not necessarily the most historical cloud provider, has entered into Enterprise Computing with a big bang. Google offers future proof infrastructure with multiple regions and zones across the globe, very strong Data & Analytics and moreover its Server less, Just code.
Google Cloud Platform has three major constituents:
- Data Center
- POP : Points Of Presence
- GGC: Google Global Cache
Implementation
AWS
AWS provide a nice easy page (https://aws.amazon.com/developers/getting-started/) to start with their services. They have categorized services platform wise and provide sample code to begin the integration.

Azure
Having developers and operations in mind, Azure also makes it simplified and easier for the users to start with their services with detailed guides.
Microsoft Azure ranks highest in Development and Testing tools with excellent links with Microsoft on-premise systems such as Windows Server, System Center and Active Directory. It also has strong PaaS capabilities; however downside is its outages and limitation for supporting other platforms. Azure offers Virtual Machines, Cloud Services and Resource Manager for App Development and Auto-scaling.
GCP
Like AWS and Azure GCP also provide some starting documentation and list some useful benefits, see below.
Pricing
Best part about the pricing for clouds is all the three offer competitive pricing, they all are fighting to grab as much space as possible to migrate workloads to cloud. This war has commoditized this space to a great extent, to benefit the users, in return the providers will get recurring revenue. With open, transparent and pay per use per workload and minutes is particularly helpful to the small and medium business user.
Also as an organization you just have to register your activities and the cloud will adjust accordingly.
AWS
The three-tier model, according to storage of Amazon Web Services is very helpful if you just need to put some data in the cloud. However, when it comes to storing 50TB – 500TB, the price difference isn’t that large, more so for feature differences, So ideally Amazon is great for large databases.
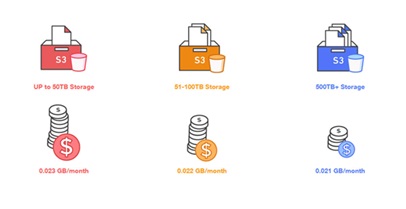
Helpful Resources
TCO is important in building a business case and gaining a better estimation of what is needed to hit organisational needs.
Azure
Azure also has a breakdown of the various pricing situations, When it comes to moving applications into the cloud, their pricing is more aggressive than Amazon and Google, owing to their desire to lead this segment of the cloud.
Helpful Resources
For Azure, the TCO calculator answers the following questions:
Would you like to lower the total cost of ownership of your on-premises infrastructure?
What are the estimated cost savings of migrating application workloads to Microsoft Azure?
GCP
Being a late entrant, Google’s pricing model attempts to beat or go head-to-head with its core competitors, billing based on exact usage. Google is also giving $300 credit for anyone to start with GCP.
Here are some of their core pricing values:
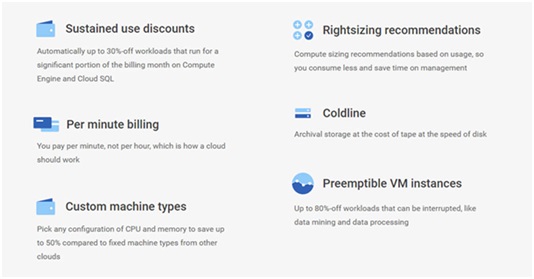
PROS & CONS
| Cloud | Pros | Cons |
| AWS | Massive scope of operations. Has a huge and growing array of available services with a comprehensive network of worldwide data centers. | Costly and ambigous cost structure |
| Azure | Tightly integrated with the microsoft applications, Existing Microsoft customers or enterprises that use a lot of Microsoft software find it logical to go for Azure. There is significant discounts off service contracts for existing Microsoft enterprise customers. |
Microsoft Azure’s service experience feels less enterprise-ready than they expected. Customers cite issues with technical support, documentation, training and breadth of the ISV partner ecosystem. Also Azure doesn’t offers as much support for DevOps approaches as integrated automation as some of the other cloud platforms. |
| GCP | Google has a strong offering in containers, since Google developed the Kubernetes standard that AWS and Azure now offer. GCP specializes in high compute offerings like Big Data, analytics and machine learning. It also offers considerable scale and load balancing – Google knows data centers and fast response time. Google offers deep discounts and flexible contracts with commitment to open source and DevOps expertise. | Google entered late and is a distant third in market share, it doesn’t offer as many different services and features as AWS and Azure, although it is quickly expanding and GCP is increasingly chosen as a strategic alternative to AWS by customers whose businesses compete with Amazon, more open-source-centric or DevOps-centric. |
AWS, Azure, Google: Vendor Pages
The following are links to the AWS’s, Azure’s and Google’s own pages about a variety of tools, from compute to storage to advanced tools:
So you got features, implementation, pricing, pros & cons and useful links, a fairly lengthy blog for a serious read and consideration.
While you may not easily come to a conclusion, at least you will hopefully have the knowledge to make a balanced decision.
In general, You can focus on your organization’s priorities that provide the most value to your organization.
Unfortunately, we often see organisations that are so committed to AWS for example, that they fail to recognize possibly more economic, and efficient alternatives. The levels of cloud tiers do vary greatly and it’s good to compare them against your requirement.
Well, that’s our summary, make sure to let us know which of AWS vs Azure vs Google Cloud wins in your mind below. For more information write to me at atul@nexcenglobal.com
All the best!





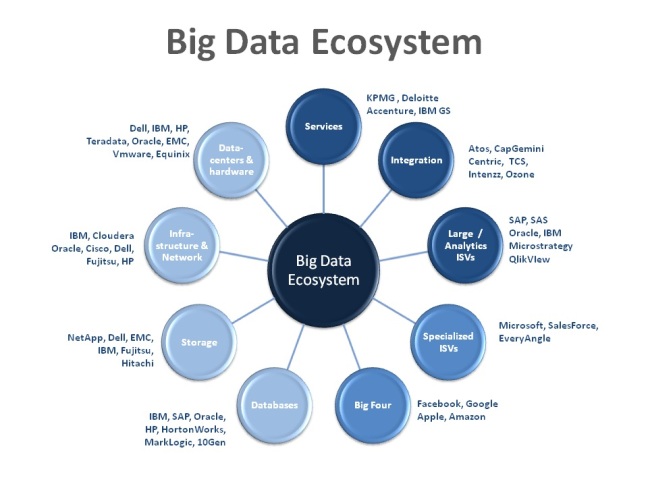
 As we welcome the new year 2018, I clearly see the emerging trends leading to Big Data. Calling it a revolution as it has changed the whole perspective and paradigm to look and treat the data. With high speed internet becoming more and more handy with masses with FTTH (Fiber To The Home) technology coupled with falling prices of broadband data connection, AI, Augmented Intelligence with Machine Learning getting wider acceptance across Enterprise IT World, the apprehensions about data security getting busted and low cost of high speed and storage resulting in high volumes of data; all lead to growing demand of Big Data.
As we welcome the new year 2018, I clearly see the emerging trends leading to Big Data. Calling it a revolution as it has changed the whole perspective and paradigm to look and treat the data. With high speed internet becoming more and more handy with masses with FTTH (Fiber To The Home) technology coupled with falling prices of broadband data connection, AI, Augmented Intelligence with Machine Learning getting wider acceptance across Enterprise IT World, the apprehensions about data security getting busted and low cost of high speed and storage resulting in high volumes of data; all lead to growing demand of Big Data.