
Let us first understand What is Hadoop, MapReduce, Big Data Framework and Spark
Hadoop is an Open Source framework for writing applications to processes structured, semi-structured or unstructured data that are stored in HDFS. Essentially Haddop is a distributed data infrastructure: Hadoop MapReduce is designed to distribute massive data collections across multiple nodes within a cluster of commodity servers, which means you don’t need to buy and maintain expensive custom hardware. It also indexes and keeps track of that data, enabling big-data processing and analytics far more effectively than was possible previously.
Hadoop is Scalable, and Fault tolerant framework written in Java. Hadoop is not only a storage system but is a platform for large data storage as well as processing.
Spark, on the other hand, is a data-processing tool that operates on those distributed data collections; it doesn’t do distributed storage.
Apache Spark is an Open Source Big Data framework. It is faster and more general purpose data processing engine and is basically designed for fast computation. It covers a wide range of workloads such as batch, interactive, iterative and streaming.
So essentially Spark is a In-Memory Cluster Processing Framework while MapReduce involves multiple read-writes on disks.
Spark performs better than Hadoop when:
- data size ranges from GBs to PBs
- there is a varying algorithmic complexity, from ETL to SQL to machine learning
- low-latency streaming jobs to long batch jobs
- processing data regardless of storage medium, be it disks, SSDs, or memory
But if the size of the data is small (~100 MB) Hadoop can sometimes be faster when performing mapping in the data nodes.
Hadoop is used for Batch processing whereas Spark can be used for both. In this regard, Hadoop users can process using MapReduce tasks where batch processing is required. In theory, Spark can perform everything that Hadoop can and more. Thus it becomes a matter of comfort when it comes to choosing Hadoop or Spark.
Lets do some point wise comparison:
1. Speed:
Apache Spark – Spark is lightning fast cluster computing tool. Apache Spark runs applications up to 100x faster in memory and 10x faster on disk than Hadoop. Because of reducing the number of read/write cycle to disk and storing intermediate data in-memory Spark makes it possible.
Hadoop MapReduce – MapReduce reads and writes from disk, as a result, it slows down the processing speed.
2. Difficulty:
Apache Spark – Spark is easy to program as it has tons of high-level operators with RDD – Resilient Distributed Dataset.
Hadoop MapReduce – In MapReduce, developers need to hand code each and every operation which makes it very difficult to work.
3. Easy to Manage
Apache Spark – Spark is capable of performing batch, interactive and Machine Learning and Streaming all in the same cluster. As a result makes it a complete data analytics engine. Thus, no need to manage different component for each need. Installing Spark on a cluster will be enough to handle all the requirements.
Hadoop MapReduce – As MapReduce only provides the batch engine. Hence, we are dependent on different engines. For example- Storm, Giraph, Impala, etc. for other requirements. So, it is very difficult to manage many components.
4. Real-time analysis
Apache Spark – It can process real time data i.e. data coming from the real-time event streams at the rate of millions of events per second, e.g. Twitter data for instance or Facebook sharing/posting. Spark’s strength is the ability to process live streams efficiently.
Hadoop MapReduce – MapReduce fails when it comes to real-time data processing as it was designed to perform batch processing on voluminous amounts of data.
5. Fault tolerance
Apache Spark – Spark is fault-tolerant. As a result, there is no need to restart the application from scratch in case of any failure.
Hadoop MapReduce – Like Apache Spark, MapReduce is also fault-tolerant, so there is no need to restart the application from scratch in case of any failure.
6. Security
Apache Spark – Spark is little less secure in comparison to MapReduce because it supports the only authentication through shared secret password authentication.
Hadoop MapReduce – Apache Hadoop MapReduce is more secure because of Kerberos and it also supports Access Control Lists (ACLs) which are a traditional file permission model.
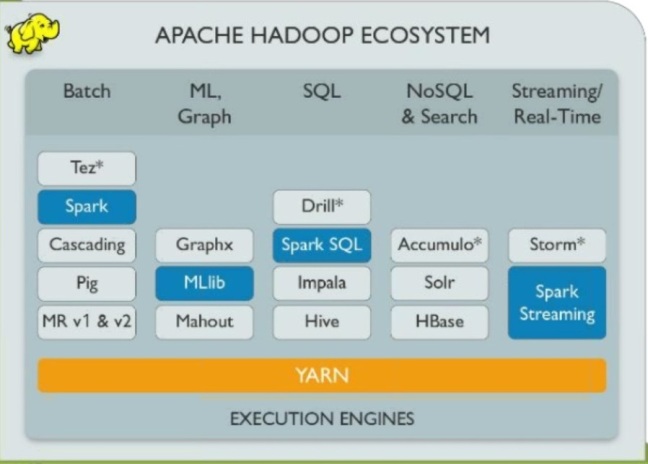
Hadoop Structure
Hadoop is a Big Data tool which has three major layers:
- HDFS – Storage Layer
- Mapreduce – Processing Layer
- Yarn – Resource Management Layer (Yet Another Resource Negotiator)
Spark on the other hand is another Processing Layer. It uses HDFS as storage layer and Yarn for Resource management. Spark does not have it’s Storage layer and it is dependent on third party i.e. HDFS.
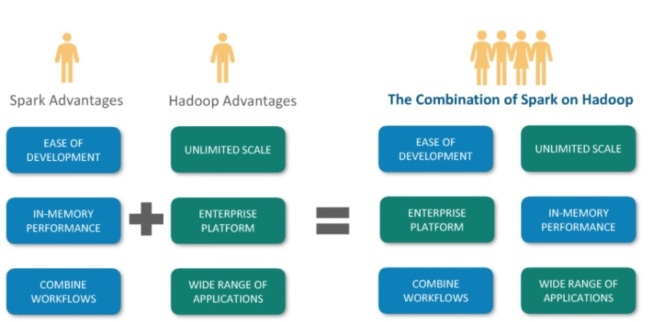
Hadoop is still the Backbone of Big Data and in Good demand.
Spark is the next stage in the evolution of this. The fundamental thinking is that fine grained mutable state is a very low level abstraction and building block for ML algorithms ; Hence Spark was an attempt to raise this abstraction to coarse grained immutable data called RDD’s ( Resilient DIstributed DataSets) ;
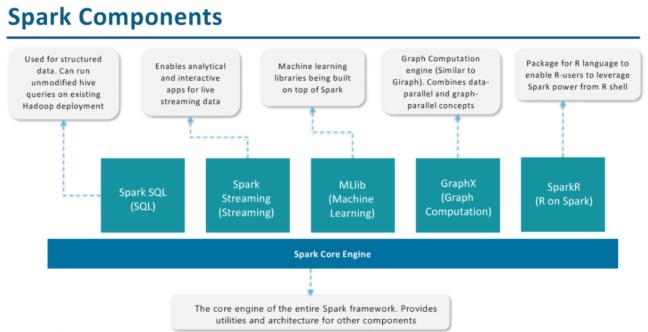
Since HDFS never really supported multiple writer concurrent appends anyway , it follows that RDD’s are not giving up much by being immutable – whereas you gain a lot by having both immutability and a higher level of abstraction to begin with for big data.
Use-cases where Spark fits best:
Real-Time Big Data Analysis:
Real-time data analysis means processing data generated by the real-time event streams coming in at the rate of millions of events per second, Twitter data for instance. The strength of Spark lies in its abilities to support streaming of data along with distributed processing. This is a useful combination that delivers near real-time processing of data. MapReduce is handicapped of such an advantage as it was designed to perform batch cum distributed processing on large amounts of data. Real-time data can still be processed on MapReduce but its speed is nowhere close to that of Spark.
Spark claims to process data 100x faster than MapReduce, while 10x faster with the disks.
Graph Processing:
Most graph processing algorithms like page rank perform multiple iterations over the same data and this requires a message passing mechanism. We need to program MapReduce explicitly to handle such multiple iterations over the same data. Roughly, it works like this: Read data from the disk and after a particular iteration, write results to the HDFS and then read data from the HDFS for next the iteration. This is very inefficient since it involves reading and writing data to the disk which involves heavy I/O operations and data replication across the cluster for fault tolerance. Also, each MapReduce iteration has very high latency, and the next iteration can begin only after the previous job has completely finished.
Also, message passing requires scores of neighboring nodes in order to evaluate the score of a particular node. These computations need messages from its neighbors (or data across multiple stages of the job), a mechanism that MapReduce lacks. Different graph processing tools such as Pregel and GraphLab were designed in order to address the need for an efficient platform for graph processing algorithms. These tools are fast and scalable, but are not efficient for creation and post-processing of these complex multi-stage algorithms.
Introduction of Apache Spark solved these problems to a great extent. Spark contains a graph computation library called GraphX which simplifies our life. In-memory computation along with in-built graph support improves the performance of the algorithm by a magnitude of one or two degrees over traditional MapReduce programs. Spark uses a combination of Netty and Akka for distributing messages throughout the executors. Let’s look at some statistics that depict the performance of the PageRank algorithm using Hadoop and Spark.
Iterative Machine Learning Algorithms:
Almost all machine learning algorithms work iteratively. As we have seen earlier, iterative algorithms involve I/O bottlenecks in the MapReduce implementations. MapReduce uses coarse-grained tasks (task-level parallelism) that are too heavy for iterative algorithms. Spark with the help of Mesos – a distributed system kernel, caches the intermediate dataset after each iteration and runs multiple iterations on this cached dataset which reduces the I/O and helps to run the algorithm faster in a fault tolerant manner.
Spark has a built-in scalable machine learning library called MLlib which contains high-quality algorithms that leverages iterations and yields better results than one pass approximations sometimes used on MapReduce.
Fast data processing. As we know, Spark allows in-memory processing. As a result, Spark is up to 100 times faster for data in RAM and up to 10 times for data in storage.
Iterative processing. Spark’s RDDs allow performing several map operations in memory, with no need to write interim data sets to a disk.
Near real-time processing. Spark is an excellent tool to provide immediate business insights. This is the reason why Spark is used in credit card’s streaming system.
It should be borne in mind that this answer leans heavily on fast, speed-of-thought analytics and ML perspective. Also, I will only consider scenarios that I actually observed people trying to use Spark for.
ETL+wrangling:
Do you have engineers that are capable of writing decent, most importantly, legible Scala? If no, probably stay with Hadoop. Unless there are other, non-technical goals (like a renewed marketing message).
Do you run, by any chance, interactive, selective, speed-of-thought queries (think OLAP)?
If yes, then no, Spark is not a spatial indexer. It can do it, but it will be locked to a “full table scan” solution, which means it will do it, on average, at a 1000x higher cost than necessary, with the QPS 1000x lower than actually is feasible, for any average pivoting UI scenario.
Oh, but then, there are no true distributed, “big data” MOLAP solutions with a good distributed spatial index scanning in OSS domain today (no, e.g. Impala does not qualify as spatial scan engine), so… maybe; but try commercial vendors perhaps instead. What you gain in software license costs, you most likely will lose on hardware and programming effort tenfold, if you do not.
Either way, MapReduce cannot do it either.
If you only run queries that are always best optimized with a “full table scan” (i.e. low selectivity queries), or do ETL type of things only, sure, go ahead. SparkQL is pretty good for that and is fairly easy.
ML (Machine Learning):
Is the speed or interactivity of the ML computations important?
If yes, then most likely one needs to move beyond Spark. Spark, as far as numerical, iterative, shared-nothing platforms go, is about the slowest platform there is. Practically everything else that exists for that purpose (except for the Hadoop variety of MapReduce of course), has far better strong scaling properties than Spark; even in the free software realm.
There are two main problems with Spark that prevent it form being on par with the segment leaders for performance: (a) a fine-grain, centralized, heavy-weight task scheduling, and (b) lack of efficient multicast programming model (as in MPI, GraphLab). This is illustrated, for example, here: Large Scale Machine Learning and Other Animals, and is true for any numerical solution that needs to iterate till convergence (which is almost everything there is). This may be a bit dated, but nothing has changed materially to date in this department.
This is especially bad with “super-step” architectures (i.e. GraphX vs. GraphLab).
If no, the described performance issues may be acceptable in your case upon evaluation; but keep in mind that there are much (much!) faster things around here that may collapse your hardware requirements potentially 100x times for a solution of equivalent volume and accuracy.
Are you designing your own ML algorithms?
If yes, you also probably need to move beyond Spark. Semantically, better choices for tensor math include BidMat/BidMach, SystemML and Mahout Samsara.
If you are going to do off-the-shelf work only, then maybe staying with Spark is fine iff your needs are completely covered with what exists today in MLLib or any other math that runs on Spark (there is more than one choice, by now).
Both ML + ETL:
Realistically, the only reason to switch to Spark rather than anything else for any decision branch that includes ML component is when operational aspects trump performance requirements.
I.e. if you can say, “I am ok with my thing running for hours on dozens of nodes, while it really computes on couple of machines in the same time elsewhere, but i have single machine cluster deployment to care about for all of ETL, batch analytics, and slow-ish, mostly non-interactive ML”, then yes. Switch to Spark.
In either case, ML on Hadoop variety of the Mapreduce is dead. Has been for at least past 3 years.
Streaming maybe? Intra-day metric aggregators? Some online inference even?
Yes, sure. Spark; but it may be worth to look at Flink, since it is said to be a “true streaming” platform, whereas Spark is said to be a microbatch emulation of streaming. In the end this distinction may not be significant to you enough though. (disclosure: I do not have a first hand experience with the Apache Flink).
That said, as others have mentioned, even if you switch to Spark, you do away with MR ecosystem (MapReduce, Pig, Hive etc.) but not some form of a Hadoop HDFS substrate. Which means, you’d still most likely be heavily married to one of Hadoop distributions out there.
So, the correct statement is MapReduce is being Replaced by Spark and not Hadoop as a whole. IF you are planning to learn Hadoop or make a future in it, please go ahead, it is not dying or dead. Big data is growing fast in leaps and bounds, it’s time to switch. Read also: The Digital World
For more information on Big Data consulting write to me atul@nexcen.in
